
What a zinger of a title 😆. Yes, casual reader, this topic is probably as boring as it sounds. I take no offense in you leaving now. If you’re still reading, it’s because you also must accomplish the title’s task, and probably encountered one of the dozen issues I will describe. I am sorry, but continue reading, I hope this will help.
What’s This About?
For the 2019 Tax Season, the Canadian Revenue Agency (CRA) gave new instructions that institutions now need to send them an electronic report of all the T2202 forms they issued to students in 2019.
This electronic report is to be an XML file, meeting the specifications defined in their schema files, as mentioned in their guide and “schema” description pages (which are a strange combination of XML and comments.)
Why Is This Anything Noteworthy?
XML is an epic file format. It became so over-engineered and confusing that the software industry has been steering clear of it for a decade. Except government.
Also, the school’s system at Pacific Rim Early Childhood Institute Inc, who employs me part-time, is written in Python 2. If I weren’t messing around with this XML report, I would have been working on updating it to Python 3 😅.
Lastly, as if making XML and Python 2 play nice wasn’t going to be interesting enough, some good ol’ mistakes and lack of real documentation made this project a real doozy.
So if you have a similar task, I think reading over what I did, what things I learned, and what challenges I had to overcome, may be helpful. Let’s get started.
Downloading the SCHEMA files
Ok, so I already have Python 2 setup on a server, with a site running on Django (but the web framework really didn’t play a part in any of this.)
I went to the CRA’s guide Filing Information Returns Electronically (T4/T5 and other types of returns) – How to file . Halfway down the page is a link to download the information schema to be used in 2020. I downloaded it to my local machine. (Spoiler! If you’re following along, don’t do that. At the time of writing, their file has a bunch of problems in it!)
I unzipped the file, and found it contained a handful of XSD files.
In case you’re rusty on what XSD files are, this tutorial may be helpful. But they define the structure (or schema) of the XML file you need to create.
Classically there’s just one, but like CSS or Javascript and other programming languages, one file can reference/import from other files. And sometimes programmers think they’re doing you a service by splitting things up into lots of files.
Generating Python Classes from the XSD Files
Now that I had the XSD files, I didn’t want to have to read through them manually to determine the structure of the XML file I wanted (full disclosure: I have needed to anyway 😩). It’s best to instead have a program read through it all, and generate code you can use.
I searched around, and the tool I ended up using was GenerateDS. It’s a command line tool, written in Python, that will take the XSD files as input, and create Python classes as the output.
GenerateDS’s documentation mentions a few ways to download it, but the easiest I found was to use the Python package manager pip (I already had it installed, so may as well.)
I ran pip install generateDS on the server, and it took care of downloading generateDS, its dependencies, and added the binary file generateDS onto the path so I could use it as a command from anywhere.
Given a valid XSD file, generateDS makes generating XML to meet that schema easy. You’re supposed to be able to just run a command like generateDS -o cra.py -s subcra.py schema.xsd and it will read schema.xsd and then write a bunch of Python classes to cra.py and subcra.py. All you need is a valid XSD file… It turned out just getting that wasn’t as easy as planned.
Problems in the XSD Files I Was Given
Python 2 Often Chokes on Accented Characters
The first problem I faced in using these files was the occasional accented characters they contain. One of the big differences between Python 2 and Python 3 is support for these special characters (Python 2 can support it, like I blogged a while ago, but you need to explicitly enable it; and code that works with Python 2 and 3 can easily overlook this.)
When I ran the generateDS on the original XSD files, I got this error:
Traceback (most recent call last):
File "/usr/local/bin/generateDS", line 11, in <module>
sys.exit(main())
File "/usr/local/bin/generateDS.py", line 8752, in main
superModule=superModule)
File "/usr/local/bin/generateDS.py", line 8166, in parseAndGenerate
prefix, root, options, args, superModule)
File "/usr/local/bin/generateDS.py", line 7917, in generate
generateSimpleTypes(wrt, prefix, SimpleTypeDict, root)
File "/usr/local/bin/generateDS.py", line 7846, in generateSimpleTypes
writeEnumClass(simpleType)
File "/usr/local/bin/generateDS.py", line 7815, in writeEnumClass
output += docstring if docstring else ''
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 306: ordinal not in range(128)I suspect that’s only a problem with generateDS when using Python 2 on XSD files with accented characters. So I manually scanned through them and removed all the accented characters from the descriptions. That removed that error.
Finding the “Main” XSD File
The next problem I discovered was that I didn’t know which was the “main” XSD file. Like I mentioned before, I was given a ZIPped folder (xmlschm1-20-3.zip) containing a half dozen XSD files, but generateDS expects one: the one that actually describes the top-level element of the XML file you’re supposed to be generating. The other ones were all imported by that main one, and so only describe part of the schema- and no where did the CRA actually say which one to use (that’s like them giving you several pages of instructions, but in a random order so you don’t know where to start.)
At first I assumed it was the one with a name matching what I wanted to generate: t2202.xsd (for making a T2202 tax form). Using generateDS on it initially worked, but didn’t produce anything actually usable. I realized the file didn’t define any elements I was supposed to put in the XML file. It just defined types. So I hunted around for a file that actually defined a top-level element. Eventually, I found layout-topology.xsd, which was it.
I went to the folder with the XSD files, and ran generateDS -o cra.py -s subcra.py layout-topology.xsd. That’s where I got the next problem…
The Provided XSD Files Were Incomplete
When I ran generateDS on layout-topology.xsd, I got this error:
Traceback (most recent call last):
File "/usr/local/bin/generateDS", line 11, in <module>
sys.exit(main())
File "/usr/local/bin/generateDS.py", line 8752, in main
superModule=superModule)
File "/usr/local/bin/generateDS.py", line 8145, in parseAndGenerate
no_redefine_groups=noRedefineGroups,
File "/usr/local/bin/process_includes.py", line 180, in process_include_files
infile, outfile, inpath, options)
File "/usr/local/bin/process_includes.py", line 493, in prep_schema_doc
schema_ns_dict, rename_data, options)
File "/usr/local/bin/process_includes.py", line 350, in collect_inserts
rename_data, options)
File "/usr/local/bin/process_includes.py", line 362, in collect_inserts_aux
string_content = resolve_ref(child, params, options)
File "/usr/local/bin/process_includes.py", line 317, in resolve_ref
raise SchemaIOError(msg)
process_includes.SchemaIOError: Can't find file ../xmlschm1-20-3-ascii/t4.xsd referenced in ../xmlschm1-20-3-ascii/complex.xsd.
Exception SystemError: '../Objects/codeobject.c:64: bad argument to internal function' in <generator object at 0xb675761c> ignoredI looked inside the XSD file, and sure enough there was an import line referencing a file named t4.xsd, but the zip they provided didn’t have it. Some engineer at the CRA left it out 😒.
I double-checked I downloaded the right ZIP file, and I did. But I also noticed the previous year’s ZIP file, xmlschm1-19-1.zip, did contain those missing files. So I manually merged the two folders 😫 (when both folders had the same file, I kept the one from the newer zipped folder, xmlschm1-20-3).
Here’s a copy of the working zip I created, in case you want it:
Then, with a complete schema, I re-ran generateDS -o cra.py -s subcra.py layout-topology.xsd, and it worked 😍: cra.py and subcra.py were full of Python classes derived from the plethora of XSD files I had been given.
Using the Python Classes Generated by generateDS
Making The Python Classes Usable
Before I started using the auto-generated code, I had to do a couple things.
Inside subcra.py, in the line import ??? as supermod change ??? to be whatever the module name is for where the files are located. I put them inside my project in libs/cra/, so I changed the line to import libs.cra.cra as supermod.
I also needed to make sure the folder that contains cra.py and subcra.py also had a __init__.py file, so that Python recognizes it as a python module, and I can then use them from elsewhere in my code.
It’s Still Important to Understand XSD Files
At one point I thought using generateDS would mean I wouldn’t need to read and understand the XSD files. That would have been great, but it didn’t turn out that way.
It seems the classes generated by generateDS allow you to make syntactically-correct XML, but they only do a bit of validation for you, and they’re not terrifically documented. So by themselves, it’s hard to know what arguments you can pass the classes’ constructor and methods. For that, you need to read the XSD files.
If you’re like me and rusty on the format of XSD files, it’s probably good to review the W3 XML Schema Tutorial. That’ll remind you about Elements, Simple Types, Complex Types, and all that.
So it’s helpful to open up the top-level XSD file, in this case layout-topologie.xsd. After the opening line that declares the file to be XML, and some comments, it contains this:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<!-- @@@@@@ Include Related Schemas @@@@@@ 2019/May/7 Version# 1.19 (version #.yy)-->
<xsd:include schemaLocation="simple.xsd"/>
...tons of other schemas...
<xsd:include schemaLocation="t2202.xsd"/> <!-- Add T2202 May 2019 -->
<xsd:include schemaLocation="frms.xsd"/>
<!-- @@@@ Common Record Layout @@@@ -->
<xsd:element name="Submission" type="ReturnType"/>
<xsd:complexType name="ReturnType">
<xsd:sequence>
<xsd:element name="T619" type="TransmitterType"/>
<xsd:element name="Return" type="ReturnChoiceType" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="TransmitterType">
<xsd:all>
<xsd:element name="sbmt_ref_id" type="char8Type"/>
<xsd:element name="rpt_tcd" type="otherDataType"/>
<xsd:element name="trnmtr_nbr" type="transNbrType"/>
<xsd:element name="trnmtr_tcd" type="indicator1-4Type" minOccurs="0"/>
<xsd:element name="summ_cnt" type="int6Type"/>
<xsd:element name="lang_cd" type="languageType"/>
<xsd:element name="TRNMTR_NM" type="Line2Type"/>
<xsd:element name="TRNMTR_ADDR" type="CanadaAddressType"/>
<xsd:element name="CNTC" type="ContactType"/>
</xsd:all>
</xsd:complexType>
</xsd:schema>So it first includes all the other XSD files, then finally mentions the top-level element: Submission, which it says is of type ReturnType. So with that we know the XML will need to look something like this:
<Submission>
...
</Submission>But what attributes can Submission have? And what’s the next element under it? We need to find where its type, ReturnType is declared… It could be in any of those other XSD files, but, this time, it’s on the very next line.
<xsd:complexType name="ReturnType">
<xsd:sequence>
<xsd:element name="T619" type="TransmitterType"/>
<xsd:element name="Return" type="ReturnChoiceType" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>So ReturnType is a complex type, meaning it has sub-elements, named T619 and Return (in that sequence), of types TransmitterType and ReturnChoiceType, respectively. Oh, and there can be as many Return elements as we want. So we know a little bit more about the XML we want:
<Submission>
<T619>...</T619>
<Return>...</Return>
...
<Return>...</Return>
</Submission>And from there, we need to find where the types TransmitterType and ReturnChoiceType are declared. Once we find them, we’ll know we’ll need to add them, and find the types of their child elements, etc. (By the way, TransmitterType is in this same file, but ReturnChoiceType is elsewhere… I used grep ReturnChoiceType * from the command-line to find that it was in frms.xsd.)
So that’s how it goes with understanding the XSD file. You could start building the XML from basic strings, based on what you’ve read in the XSD file. But there’s quite a bit of repetitive code you’ll need, which generateDS took care of for us. But for that, you’re going to need to figure out how the XSD corresponds to the Python Classes.
Mapping XML Tags to Python Classes
Simple Types map to Python built-in types (eg unicode strings, ints, floats, etc); whereas XML complex types map to Python classes (that were placed in cra.py by GenerateDS for you.) But which ones?
Each complex type declared in the XSD files corresponds to a Python Class by the same name. Eg, the top-level element was named Submission and it was of type ReturnType. So I searched through cra.py for class ReturnType, and sure enough there it was. Something like this:
class ReturnType(GeneratedsSuper):
__hash__ = GeneratedsSuper.__hash__
subclass = None
superclass = None
def __init__(self, T619=None, Return=None, gds_collector_=None, **kwargs_):
...
...then a bunch of setter and getter methods
...and some export methods (for making the XML)
...and some build methods (for interpreting XML)So in there we see what arguments we can pass to this class: T619, Return, and something called gds_collector (not sure what that one was for.)
So the Python code to generate that could look like
from libs.cra.cra import ReturnType
submission = ReturnType(T619=None, Return=None)If you’re like me, at this point you’re dying to make at least the tinyest XML file to confirm you’re on the right track. So you can use that submission to generate a string of XML with the following
import StringIO
output = StringIO.StringIO()
submission.export(output, 0, name_='Submission')
generated_xml = output.getvalue()Print that generated_xml out to the page, console, or to a file, whatever. It should produce glorious XML like the following:
<Submission></Submission>To add the sub-elements, T619 and Returns, you need to:
- find where those elements were declared in the XSD files (they’re part of the
ReturnTypecomplex type, located inlayout-topologie.xsd) - find their XSD types in the XSD files (they’re of type
TransmitterTypeandReturnChoiceType, respectively) - find classes in
cra.pywith the same names as those complex types (class TransmitterTypeandclass ReturnChoiceType)
Then use those classes in your code too. But what arguments do they take? Recurse (ie, start at step 1 again). Yes, it gets tedious, but you do eventually hit the bottom.
Tag Names That Differ From Their Type
Sometimes tag names differ from their type. In that case, use the Python class that corresponds to the XSD type; then set original_tagname_ to the name the tag is supposed to have; and extensiontype_ to the tag’s type. Eg
student_address_line1 = Character30TextType(
valueOf_ = student.street_address
)
student_address_line1.original_tagname_ = 'AddressLine1Text'
student_address_line1.extensiontype_ = 'Character30TextType' It’s pretty tedious. I know.
Formatting Decimal Numbers
Once I finally generated some XML, I saw the dollar amount fields were being formatted strangely: there were no numbers after the decimal place. Eg it showed “4615.” instead of “4615.00”.

Seeing how generateDS created usable Python code, I decided to try to hunt down the problem in the generated code and fix it myself.
The SchoolSession XML tag corresponded to the Python class SchoolSessionType. So I looked at its methods for generating (or “exporting”) an XML string. It had a method called export, which called exportChildren to generate the XML for the sub-tags. In that method, I saw it used self.gds_format_decimal to format the dollar amount. I found that method on GeneratedsSuper, and it looked like this:
def gds_format_decimal(self, input_data, input_name=''):
return ('%0.10f' % input_data).rstrip('0')Here, input_data is a float (or Decimal). So it’s formatting the float to have 10 decimal places ( eg 4615.0000000000), but then removing all the 0 characters on the right side of the string (eg 4615..)
So I modified the method to be this:
def gds_format_decimal(self, input_data, input_name=''):
return '%0.2f' % input_dataThat’s probably not generally good, as it forcing ALL XML that has decimal numbers to only be shown up to 2 decimal places. But I’m just working with dollars and cents, not precise scientific measurements. This produced numbers with 2 decimal places, so this did the trick.
Validating the XML Using XMLSchema Python Library
After I generated what looks like valid XML, it’s time to get a machine to run a more thorough scan of it to double-check it’s all good. For that, I found the Python library xmlschema.
While there are a ton of XML validating web services out there, they all worked with only one XSD file — not a folder full of them. Or they would use a URL to an XML schema, but I didn’t feel like uploading the directory of XML schemas I had been provided to somewhere random to get them working like that.
Plus, using a Python library allows me to automatically run the validation before generating the XML file, rather than making running validation on the generated XML file manually-invoked process.
Installing and using the library was super easy: pip install xmlschema. Then after my code had generated the XML, I ran
from xmlschema import XMLSchema
schema = XMLSchema('libs/cra-xsds/layout-topologie.xsd')
schema.validate(generated_xml)If there was a validation error, I’d get an exception with a ton of helpful details, like the following:
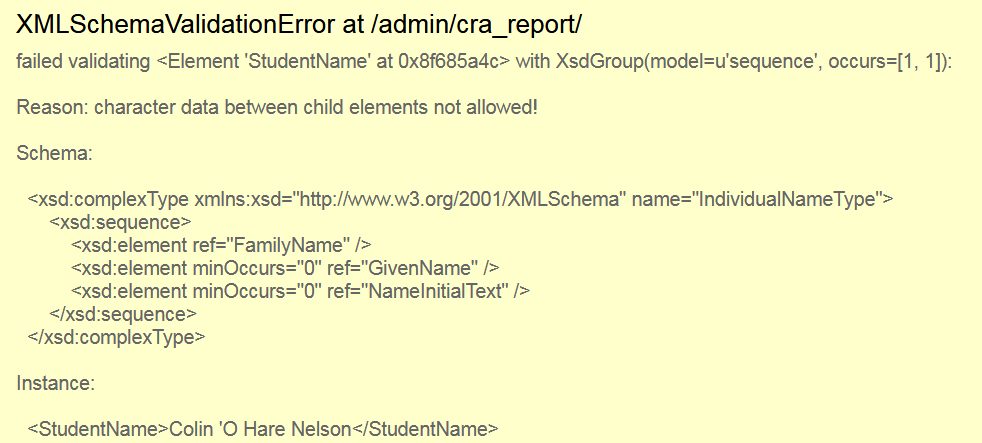
Here it’s telling me the xml <StudentName>Colin 'O Hare Nelson</StudentName> is invalid because “character data between child elements not allowed”, and it even shows the relevant section of the XSD file that describes what the XML should look like. It seems I had incorrectly thought StudentName was a simple XML element, but it’s actually a complex XML element with sub-elements FamilyName (required), GiveName (optional), and NameInitialText (optional).
While I was resolving some validation issues regarding how I generated the XML, I discovered a couple issues that seem to have been more generateDS’s fault.
StudentName is a complex type, not a simple type
One of the validation errors I got was this:
XMLSchemaValidationError at /admin/cra_report/
failed validating <Element ‘StudentName’ at 0x8f5749ac> with XsdGroup(model=u’sequence’, occurs=[1, 1]):Reason: character data between child elements not allowed!
Somehow the generated Python class for T2202SlipType thought its child element StudentName should be a simple type— ie a simple string. But the XSD files specifically said it needed to be a complex type (an element with sub-elements). So I needed to manually fix the Python class T2202SlipType‘s method exportChildren, where it said
if self.StudentName is not None:
namespaceprefix_ = self.StudentName_nsprefix_ + ':' if (UseCapturedNS_ and self.StudentName_nsprefix_) else ''
showIndent(outfile, level, pretty_print)
outfile.write('<%sStudentName>%s</%sStudentName>%s' % (namespaceprefix_ , self.gds_encode(self.gds_format_string(quote_xml(self.StudentName), input_name='StudentName')), namespaceprefix_ , eol_))I had to replace it with the following:
if self.StudentName is not None:
namespaceprefix_ = self.StudentName_nsprefix_ + ':' if (UseCapturedNS_ and self.StudentName_nsprefix_) else ''
self.StudentName.export(outfile, level, namespaceprefix_, namespacedef_='', name_='StudentName', pretty_print=pretty_print)
Pretty Print Adding Extra Whitespace
I also found generateDS’s “pretty print” option was sometimes randomly adding a ton of whitespace inside elements, which made them invalid if they had a character limit.
For example, look at this XML it generated:
<ContactInformation>
<ContactName>George Arbuckle </ContactName>
<ContactAreaCode>250</ContactAreaCode>
<ContactPhoneNumber>652-1234</ContactPhoneNumber>
</ContactInformation>See how the tag ContactName has a TON of whitespace after its content “George Arbuckle”? That was being added by GenerateDS (it’s not part of my data).
Turning pretty printing off fixed it. Eg
submission.export(output, 0, name_='Submission', namespacedef_=XMLNS, pretty_print=False)Element Body Mysteriously becoming its Type
I also got an error like
XMLSchemaKeyError at /admin/cra_report/
u”missing an XsdSimpleType or XsdComplexType component for ‘George Arbuckle’! As the name has no namespace maybe a missing default namespace declaration.”
I was quite confused by this. If I had requested to make an element of type “George Arbuckle” I think I would have remembered that. In the XML I saw this:
<ContactInformation>
<ContactName xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="George Arbuckle">George Arbuckle </ContactName>
<ContactAreaCode>250</ContactAreaCode>
<ContactPhoneNumber>652-1234</ContactPhoneNumber>
</ContactInformation>
I had no idea where xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="George Arbuckle" was coming from. The Python code in-use was:
contact_name = ContactName(
valueOf_=TRANSMITTER_NAME_LINE1[:22],
)
contact_info = ContactType3(
ContactName = contact_name,
ContactAreaCode=TRANSMITTER_AREA_CODE,
ContactPhoneNumber=TRANSMITTER_PHONE
)
contact_info.original_tagname_ = 'ContactInformation'
contact_info.extensiontype_ = 'ContactType3'I noticed in the XML schema though, that this tag ContactInformation was optional. So I just gave up trying to add it. (If you know the actual reason for the error please comment!)
The Final Code
Here’s some snippets from the final code I have running. Some of it is specific to Django and our custom code, but I think it will still be helpful.
Here’s a bit from my Django view views.py contains a function that triggers generating the XML file when you visit a page:
def cra_report(request):
response = http.HttpResponse(content_type="text/xml")
response['Content-Disposition'] = 'attachment; filename=cra-report-2019.xml'
response.write(generate_cra_t2202_report_xml(2019))
return responseIts calling this follwoing method, generate_cra_t2202_report_xml which actually generates the XML. Note that libs.cra.cra is the code I generated using GenerateDS. libs.cra.constants are simple values specific to our institution, with the exception of XMLNS which was so long I didn’t want to clutter the code with it. Its value is:
xmlns:ccms="http://www.cra-arc.gc.ca/xmlns/ccms/1-0-0" xmlns:sdt="http://www.cra-arc.gc.ca/xmlns/sdt/2-2-0" xmlns:ols="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols/1-0-1" xmlns:ols1="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols1/1-0-1" xmlns:ols10="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols10/1-0-1" xmlns:ols100="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols100/1-0-1" xmlns:ols12="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols12/1-0-1" xmlns:ols125="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols125/1-0-1" xmlns:ols140="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols140/1-0-1" xmlns:ols141="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols141/1-0-1" xmlns:ols2="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols2/1-0-1" xmlns:ols5="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols5/1-0-1" xmlns:ols50="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols50/1-0-1" xmlns:ols52="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols52/1-0-1" xmlns:ols6="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols6/1-0-1" xmlns:ols8="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols8/1-0-1" xmlns:ols8-1="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols8-1/1-0-1" xmlns:ols9="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols9/1-0-1" xmlns:olsbr="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/olsbr/1-0-1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="layout-topologie.xsd"def generate_cra_t2202_report_xml(year):
from libs.cra.cra import ReturnType, TransmitterType as XMLTransmitterType, Line2Type, CanadaAddressType, ContactType, T2202SlipType, T2202SummaryType, T2202ReturnType, ReturnChoiceType, ThreeLinedLength30NameType, Character30TextType, ContactType3, Length28NameType, RequiredLine1AddressType, ContactName
from libs.cra.constants import XMLNS, ReportType, TRANSMITTER_NUMBER, TRANSMITTER_NAME_LINE1, TransmitterType, LanguageType, TRANSMITTER_COUNTRY_CODE, TRANSMITTER_AREA_CODE, TRANSMITTER_PHONE, TRANSMITTER_EMAIL, FILER_ACCOUNT_NUMBER, ReportType
from common.constants import PACRIM_NAME, PACRIM_ADDRESS_LINE1, PACRIM_ADDRESS_CITY, PACRIM_ADDRESS_PROVINCE, PACRIM_ADDRESS_POSTAL_CODE, PACRIM_COUNTRY_CODE, COUNTRIES_ISO2_TO_ISO3
import time
transmitter_name = Line2Type(
l1_nm=TRANSMITTER_NAME_LINE1,
l2_nm=PACRIM_NAME[:30]
)
address = CanadaAddressType(
addr_l1_txt = PACRIM_ADDRESS_LINE1,
cty_nm = PACRIM_ADDRESS_CITY,
prov_cd = PACRIM_ADDRESS_PROVINCE,
cntry_cd = TRANSMITTER_COUNTRY_CODE,
pstl_cd = PACRIM_ADDRESS_POSTAL_CODE
)
contact = ContactType(
cntc_nm=TRANSMITTER_NAME_LINE1,
cntc_area_cd=TRANSMITTER_AREA_CODE,
cntc_phn_nbr=TRANSMITTER_PHONE,
cntc_email_area=TRANSMITTER_EMAIL,
)
t619 = XMLTransmitterType(
sbmt_ref_id = time.strftime("%y%m%d%H"), #8 characters, just for our internal reference. See https://www.canada.ca/en/revenue-agency/services/e-services/filing-information-returns-electronically-t4-t5-other-types-returns-overview/upcoming-year-t619.html
rpt_tcd = ReportType.ORIGINAL,
trnmtr_nbr = TRANSMITTER_NUMBER,
trnmtr_tcd = TransmitterType.OURS,
summ_cnt = 1,
lang_cd = LanguageType.ENGLISH,
TRNMTR_NM = transmitter_name,
TRNMTR_ADDR = address,
CNTC = contact
)
t619.original_tagname_ = 'T619'
t619.extensiontype_ = 'TransmitterType'
t2202s = _get_t2202_slips(year)
sum_taxable_amounts = 0
for slip in t2202s:
sum_taxable_amounts = sum_taxable_amounts + slip.get_TotalEligibleTuitionFeeAmount()
## institution name
institution_name_line_1 = Character30TextType(
valueOf_ = PACRIM_NAME[:30]
)
institution_name_line_1.original_tagname_ = 'NameLine1Text'
institution_name_line_1.extensiontype_ = 'ccms:Character30TextType'
instituiton_name_line_2 = Character30TextType(
valueOf_ = PACRIM_NAME[30:60]
)
instituiton_name_line_2.original_tagname_ = 'NameLine2Text'
instituiton_name_line_2.extensiontype_ = 'ccms:Character30TextType'
instituiton_name_line_3 = Character30TextType(
valueOf_ = PACRIM_NAME[60:90]
)
instituiton_name_line_3.original_tagname_ = 'NameLine3Text'
instituiton_name_line_3.extensiontype_ = 'ccms:Character30TextType'
institution_name_split_across_3_lines = ThreeLinedLength30NameType(
NameLine1Text=institution_name_line_1,
NameLine2Text=instituiton_name_line_2,
NameLine3Text=instituiton_name_line_3,
)
## institution address
institution_address_line1 = Character30TextType(
valueOf_ = PACRIM_ADDRESS_LINE1
)
institution_address_line1.original_tagname_ = 'AddressLine1Text'
institution_address_line1.extensiontype_ = 'ccms:Character30TextType'
institution_city = Length28NameType(
valueOf_ = PACRIM_ADDRESS_CITY
)
institution_city.original_tagname_ = 'CityName'
institution_city.extensiontype_ = 'Length28NameType'
institution_address = RequiredLine1AddressType(
AddressLine1Text = institution_address_line1,
CityName = institution_city,
ProvinceStateCode = PACRIM_ADDRESS_PROVINCE,
CountryCode = COUNTRIES_ISO2_TO_ISO3[PACRIM_COUNTRY_CODE],
PostalZipCode = PACRIM_ADDRESS_POSTAL_CODE
)
institution_address.original_tagname_ = 'PostSecondaryEducationalInstitutionMailingAddress'
institution_address.extensiontype_ = 'RequiredLine1AddressType'
t2202_summary = T2202SummaryType(
FilerAccountNumber=FILER_ACCOUNT_NUMBER,
SummaryReportTypeCode=ReportType.ORIGINAL,
FilerAmendmentNote=None,
TaxationYear=year,
TotalSlipCount=len(t2202s),
PostSecondaryEducationalInstitutionName=institution_name_split_across_3_lines,
PostSecondaryEducationalInstitutionMailingAddress=institution_address,
TotalEligibleTuitionFeeAmount=sum_taxable_amounts,
)
t2202_summary.original_tagname_ = 'T2202Summary'
t2202_summary.extensiontype_ = 'T2202SummaryType'
t2202_return = T2202ReturnType(
T2202Slip = t2202s,
T2202Summary = t2202_summary
)
xml_return = ReturnChoiceType(
T2202 = t2202_return
)
xml_return.original_tagname_ = 'Return'
xml_return.extensiontype_ = 'ReturnChoiceType'
xml_returns = [
xml_return
]
submission = ReturnType(T619=t619, Return=xml_returns)
import StringIO
output = StringIO.StringIO()
submission.export(output, 0, name_='Submission', namespacedef_=XMLNS, pretty_print=settings.PRETTY_PRINT_XML)
generated_xml = output.getvalue()
if settings.VALIDATE_XML:
# Validate it before we download it
from xmlschema import XMLSchema
schema = XMLSchema('libs/cra-xsds/layout-topologie.xsd')
schema.validate(generated_xml)
return generated_xmlThat function, in turn, uses _get_t2202_slips for getting all the XML for the individual T2202 slips. It actually retrieves our data from the database and then stuffs it into the XML.
"""
Gets all the info for T2202 slips in the given timeframe
"""
def _get_t2202_slips(year):
from libs.cra.cra import T2202SlipType, SchoolSessionType, Length1to30TextType, Length1to20TextType, RequiredLine1AddressType, RequiredLine1AddressType, Character30TextType, Length28NameType, IndividualNameType, FamilyName, GivenName
from libs.cra.constants import T2202SlipTypeCodeType
from common.constants import CRA_ACCOUNT_NUMBER, COUNTRIES_ISO2_TO_ISO3
from registration.models import Student
students = Student.objects.enrolled_between(str(year) + '-01-01', str(year + 1) + '-01-01')
slips = []
for student in students:
pdf_fields = student.t2202_fields(year)
if not 'NameProg' in pdf_fields:
continue
sessions = []
for row in ['1','2','3','4']:
a_field_from_row = 'EligTFees' + row
if a_field_from_row in pdf_fields and 'FromMonth' + row in pdf_fields:
session = SchoolSessionType(
StartYearMonth = str(pdf_fields['FromYear' + row]).zfill(2) + str(pdf_fields['FromMonth' + row]).zfill(2),
EndYearMonth = str(pdf_fields['ToYear' + row]).zfill(2) + str(pdf_fields['ToMonth' + row]).zfill(2),
EligibleTuitionFeeAmount = revert_to_float(pdf_fields['EligTFees' + row]),
PartTimeStudentMonthCount = pdf_fields['MonthsPartTime' + row],
FullTimeStudentMonthCount = 0
)
session.original_tagname_ = 'SchoolSession'
session.extensiontype_ = 'SchoolSessionType'
sessions.append(session)
program_name = Length1to30TextType(
valueOf_ = pdf_fields['NameProg'][:30]
)
program_name.original_tagname_ = 'PostSecondaryEducationalSchoolProgramName'
program_name.extensiontype_ = 'Length1to30TextType'
student_number = Length1to20TextType(
valueOf_ = pdf_fields['StuNum']
)
student_number.original_tagname_ = 'StudentNumber'
student_number.extensiontype_ = 'Length1to20TextType'
student_address_line1 = Character30TextType(
valueOf_ = student.street_address[:30]
)
student_address_line1.original_tagname_ = 'AddressLine1Text'
student_address_line1.extensiontype_ = 'ccms:Character30TextType'
student_city = Length28NameType(
valueOf_ = student.city
)
student_city.original_tagname_ = 'CityName'
student_city.extensiontype_ = 'Length28NameType'
province_code = student.province_abbrev()
student_address = RequiredLine1AddressType(
AddressLine1Text = student_address_line1,
CityName = student_city,
# Use "ZZ" if we don't know the actual code (that's what the CRA likes) not "ZY" (that's what PTIB likes)
ProvinceStateCode = province_code if province_code != 'ZY' else 'ZZ',
CountryCode = COUNTRIES_ISO2_TO_ISO3[student.country],
PostalZipCode = student.postal_code
)
student_address.original_tagname_ = 'StudentAddress'
student_address.extensiontype_ = 'RequiredLine1AddressType'
student_name = IndividualNameType(
FamilyName=FamilyName(valueOf_=student.last_name),
GivenName=GivenName(valueOf_=student.first_name[:12])
)
student_name.original_tagname_ = 'StudentName'
student_name.extensiontype_ = 'IndividualNameType'
slip = T2202SlipType(
SlipReportTypeCode=T2202SlipTypeCodeType.ORIGINAL,
FilerAccountNumber=CRA_ACCOUNT_NUMBER,
PostSecondaryEducationalSchoolProgramName = program_name,
PostSecondaryEducationalSchoolTypeCode = pdf_fields['Type'],
StudentName = student_name,
SocialInsuranceNumber = pdf_fields['StuSIN'] if pdf_fields['StuSIN'] else '000000000',
StudentNumber = student_number,
StudentAddress = student_address,
SchoolSession = sessions,
TotalEligibleTuitionFeeAmount = revert_to_float(pdf_fields['Total1']),
TotalPartTimeStudentMonthCount = pdf_fields['TotalMonthsPartTime'],
TotalFullTimeStudentMonthCount = 0
)
slips.append(slip)
return slipsAnd after all that, I was finally generating an XML file that passed validation according to the CRA’s XSD files. 🎉🎉🎉
Here’s what the generated XML looks like (just contains one slip, yours will contain multiple because there’s one for each enrolled student.)
<Submission xmlns:ccms="http://www.cra-arc.gc.ca/xmlns/ccms/1-0-0" xmlns:sdt="http://www.cra-arc.gc.ca/xmlns/sdt/2-2-0" xmlns:ols="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols/1-0-1" xmlns:ols1="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols1/1-0-1" xmlns:ols10="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols10/1-0-1" xmlns:ols100="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols100/1-0-1" xmlns:ols12="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols12/1-0-1" xmlns:ols125="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols125/1-0-1" xmlns:ols140="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols140/1-0-1" xmlns:ols141="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols141/1-0-1" xmlns:ols2="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols2/1-0-1" xmlns:ols5="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols5/1-0-1" xmlns:ols50="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols50/1-0-1" xmlns:ols52="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols52/1-0-1" xmlns:ols6="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols6/1-0-1" xmlns:ols8="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols8/1-0-1" xmlns:ols8-1="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols8-1/1-0-1" xmlns:ols9="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/ols9/1-0-1" xmlns:olsbr="http://www.cra-arc.gc.ca/enov/ol/interfaces/efile/partnership/olsbr/1-0-1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="layout-topologie.xsd">
<T619>
<sbmt_ref_id>41027516</sbmt_ref_id>
<rpt_tcd>O</rpt_tcd>
<trnmtr_nbr>MM524455</trnmtr_nbr>
<trnmtr_tcd>1</trnmtr_tcd>
<summ_cnt>1</summ_cnt>
<lang_cd>E</lang_cd>
<TRNMTR_NM>
<l1_nm>Jane Smith/l1_nm>
<l2_nm>College of Canada</l2_nm>
</TRNMTR_NM>
<TRNMTR_ADDR>
<addr_l1_txt>PO Box 999</addr_l1_txt>
<cty_nm>North Pole</cty_nm>
<prov_cd>YK</prov_cd>
<cntry_cd>CAN</cntry_cd>
<pstl_cd>H0H 0H0</pstl_cd>
</TRNMTR_ADDR>
<CNTC>
<cntc_nm>Fred smith</cntc_nm>
<cntc_area_cd>254</cntc_area_cd>
<cntc_phn_nbr>553-4021</cntc_phn_nbr>
<cntc_email_area>[email protected]</cntc_email_area>
</CNTC>
</T619>
<Return>
<T2202>
<T2202Slip>
<SlipReportTypeCode>O</SlipReportTypeCode>
<FilerAccountNumber>324105140RZ0002</FilerAccountNumber>
<PostSecondaryEducationalSchoolProgramName xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="Length1to30TextType">How To Do Things Program</PostSecondaryEducationalSchoolProgramName>
<PostSecondaryEducationalSchoolTypeCode>3</PostSecondaryEducationalSchoolTypeCode>
<StudentName>
<FamilyName>Sanchez</FamilyName>
<GivenName>Lalo</GivenName>
</StudentName>
<SocialInsuranceNumber>000000000</SocialInsuranceNumber>
<StudentNumber xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="Length1to20TextType">34003</StudentNumber>
<StudentAddress>
<AddressLine1Text xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ccms:Character30TextType">123</AddressLine1Text>
<CityName xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="Length28NameType">North Pole</CityName>
<ProvinceStateCode>YK</ProvinceStateCode>
<CountryCode>CAN</CountryCode>
<PostalZipCode>v0r 4e5</PostalZipCode>
</StudentAddress>
<SchoolSession>
<StartYearMonth>1901</StartYearMonth>
<EndYearMonth>1901</EndYearMonth>
<EligibleTuitionFeeAmount>595.00</EligibleTuitionFeeAmount>
<PartTimeStudentMonthCount>1</PartTimeStudentMonthCount>
<FullTimeStudentMonthCount>0</FullTimeStudentMonthCount>
</SchoolSession>
<TotalEligibleTuitionFeeAmount>595.00</TotalEligibleTuitionFeeAmount>
<TotalPartTimeStudentMonthCount>1</TotalPartTimeStudentMonthCount>
<TotalFullTimeStudentMonthCount>0</TotalFullTimeStudentMonthCount>
</T2202Slip>
<T2202Slip>
<SlipReportTypeCode>O</SlipReportTypeCode>
<FilerAccountNumber>
324105140RZ0002
</FilerAccountNumber>
<PostSecondaryEducationalSchoolProgramName xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="Length1to30TextType">Basket Weaving Masters</PostSecondaryEducationalSchoolProgramName>
<PostSecondaryEducationalSchoolTypeCode>3</PostSecondaryEducationalSchoolTypeCode>
<StudentName>
<FamilyName>Joshua</FamilyName>
<GivenName>Simpson</GivenName>
</StudentName>
<SocialInsuranceNumber>000000000</SocialInsuranceNumber>
<StudentNumber xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="Length1to20TextType">17496</StudentNumber>
<StudentAddress>
<AddressLine1Text xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ccms:Character30TextType">430 Greenlight Cres.</AddressLine1Text>
<CityName xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="Length28NameType">South Monkton </CityName>
<ProvinceStateCode>BC</ProvinceStateCode>
<CountryCode>CAN</CountryCode>
<PostalZipCode>V7C 4D7</PostalZipCode>
</StudentAddress>
<SchoolSession>
<StartYearMonth>1901</StartYearMonth>
<EndYearMonth>1902</EndYearMonth>
<EligibleTuitionFeeAmount>285.64</EligibleTuitionFeeAmount>
<PartTimeStudentMonthCount>2</PartTimeStudentMonthCount>
<FullTimeStudentMonthCount>0</FullTimeStudentMonthCount>
</SchoolSession>
<TotalEligibleTuitionFeeAmount>285.64</TotalEligibleTuitionFeeAmount>
<TotalPartTimeStudentMonthCount>2</TotalPartTimeStudentMonthCount>
<TotalFullTimeStudentMonthCount>0</TotalFullTimeStudentMonthCount>
</T2202Slip>
<T2202Summary>
<FilerAccountNumber>123103140RZ0002</FilerAccountNumber>
<SummaryReportTypeCode>O</SummaryReportTypeCode>
<TaxationYear>2019</TaxationYear>
<TotalSlipCount>2</TotalSlipCount>
<PostSecondaryEducationalInstitutionName>
<NameLine1Text xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ccms:Character30TextType">College of Canada</NameLine1Text>
<NameLine2Text xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ccms:Character30TextType"></NameLine2Text>
<NameLine3Text xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ccms:Character30TextType"/>
</PostSecondaryEducationalInstitutionName>
<PostSecondaryEducationalInstitutionMailingAddress>
<AddressLine1Text xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ccms:Character30TextType">234 Foo Bar St.</AddressLine1Text>
<CityName xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="Length28NameType">Danger Bay</CityName>
<ProvinceStateCode>BC</ProvinceStateCode>
<CountryCode>CAN</CountryCode>
<PostalZipCode>V0Y 1R3</PostalZipCode>
</PostSecondaryEducationalInstitutionMailingAddress>
<TotalEligibleTuitionFeeAmount>595.00</TotalEligibleTuitionFeeAmount>
</T2202Summary>
</T2202>
</Return>
</Submission>Thanks “Fuji” for suggesting pasting the actual generated XML.
Questions for the CRA
But there were still some issues about the content that weren’t quite clear. I asked the school’s accountant, who asked the CRA. Here’s the questions and their corresponding answers:
- Question: Do we send the T2202 forms to ALL students, or just to those who are enrolled in a course during the year? Answer: Only students who were enrolled during the calendar year (that’s what Algonquin does.)
- Question: If a student is enrolled in a course during 2019, but that enrollment’s payment was received in 2018, on what year do we show them as enrolled? If it’s 2019, what do we set the “Eligible Tuition Fee Amount” to? (Considering we didn’t actually receive the funds in 2019.) Answer: Ignore the payment date, only the dates of enrollment matter. Also, the amount shown should be split between the two years, proportionately to how much time of the course occurred during that calendar year. (That’s what BCIT, the University of Winnipeg, and Algonquin do; although the Michener Institute only reports them on the first year, which our accountant believes is wrong.)
- Question: If the student has not provided us with their Social Insurance Number (SIN, which the CRA now requires we collect), they said we just need to keep a record that we’ve attempted to collect it from them (otherwise there is a fine). So in some circumstances, it’s expected students will not have provided us with their SIN. But the XSD files still think it’s a requirement, and indicate the submitted XML file is invalid if the element is blank. So should we not report on students without SINs? Should we use a placeholder like “000000000”? Answer:
We should use a placeholder like “999999999” (that’s what Michener Institute does.)Update: After submitting, the CRA called us back saying we should instead use “000000000” when students have no SIN 🙃.
Conclusion
Well that was a wild ride, that’s not entirely completed. If you’re a lucky soul who’s also undergoing this task, please comment or contact me to connect. We may be able to make more sense of all this.
Similar Stuff I've Written
 Adding Support for Foreign Characters to Django
Adding Support for Foreign Characters to Django
 forwarding a post in python
KICKOFF of FBAdvancedSearch FB/Kynetx App
forwarding a post in python
KICKOFF of FBAdvancedSearch FB/Kynetx App
 Dealing with Amazon Product Advertising API Policy Changes
Dealing with Amazon Product Advertising API Policy Changes
 The 5 Promises of User-Led Software Development
The 5 Promises of User-Led Software Development
 How to Validate Freemius Licenses Outside of a Plugin
Gratitude Journal August 2018
Gratitude Journal July 2018
Making a Django Custom Model Field, Form Field, and Widget
How to Validate Freemius Licenses Outside of a Plugin
Gratitude Journal August 2018
Gratitude Journal July 2018
Making a Django Custom Model Field, Form Field, and Widget
Powered by YARPP.
Hi Michael (or is it Colin). Enjoyed your post as we are trying to do the same thing. We (Northwest Baptist Semnary) developed in-house student data software (php/mysql) and now are trying to ascertain how best to comply with CRA requirements to file T2202s. One of the things that I am unclear about is whether CRA allows us to file a single xml file with all students in it or if we have to file an individual xml for each student. What have you ascertained?
Best,
Loren
Hi Loren! Thanks for reaching out. You can send a single XML file containing multiple data for MULTIPLE T2202s.
On Chapter 5, under internet file transfer (XML) it says
All the best!
Hello! I just used Excel and dropped the Schema though the Developer add on. I had to learn about xml mapping for just single cell and repeating cells. I mapped the schema to the repeating cells by making those columns into Tables…as I was getting a Denormalized error message on export from the Excel Developer. I am not out of the woods yet!
Wow, thank you for the info. Yes, I’m doing this for a part of York University. I’ll let you know if I learn anything more.
Thanks! I hope to be submitting the XML report ASAP so we’ll see if I also have anything to add later.
Update: After submitting, the CRA called us back saying we should instead use “000000000” as the placeholder when students have no SIN 🙃.
I just added that to the body of the post too.
I think it would be useful for people to have an example of a valid XML. Beware of string lengths in the XSD as they are relatively restrictive (ex. 30 characters for address lines, 12 characters for names)
(edited by site owner, because WordPress automatically sanitized the example XML Fuji placed in here, making it not very helpful. But I updated the post to include example XML as they suggested.)
Thanks, this post was immensely helpful to me today. It seems the CRA has been pretty loose about submissions in past years, but is really cracking down on the format this time around!
Glad this was helpful, and ya the CRA does seem to be getting more strict.
The next thing they’ll need to crack down on is ensuring we’re all handling students SINs securely, as it’s a particularly sensitive piece of information we’re now required to gather.
Thank you for posting this article. It was extremely helpful for the main xsd name, validator and the Submission element,
This is great. I have to do this in C# for a T4A, but it pretty much follows the same process. I even found a code generator that creating C# classes from the XSD. Knowing the main xsd file was a big help.